Yesterday I gave a talk at php[world] 2019 about "Tips and Tools for Gluing Together the Open Web." Below are the slides, text and links from my talk. Where applicable, the slide images link to relevant websites and code.

A few months ago, I was helping a local non-profit organization with their new website. We were almost set to launch, but they had one more request: can we get the next five upcoming events we've put up on our organization's Facebook page to show up in a list in the website's footer? I initially thought that surely there would be a simple way to do this, but as I looked in to it, the short answer was no, no you can't.
There's an embeddable Facebook widget that can display events, but you don't get a lot of control over appearance and it's far from a helpful list that can be scanned quickly. This seemed like such a basic request - connecting Facebook page events to a website - and yet as I poured through Google and Stack Overflow search results all I could find were frustrated users and abandoned tools that had tried and failed to do this one thing.

Exploring this challenge reinforced a big concern I have, and it's one at the heart of my talk here today. My concern is that we are slowly accepting the version of the web that is full of closed systems, dominated by software, tools and devices that don't talk to each other.
I remember the feeling I had in the earliest days of the web and the Internet, when I learned about the network that was being connected together, piece by piece.

Across the world, people were building software that would allow information and ideas to flow freely across computer systems, institutional networks and devices that were not originally intended to talk to each other. It was such a simple idea and yet one that opened up the possibilities for collaboration, dialog, sharing and learning at an unimaginable scale. It almost seemed like magic and as I suspect is the case for many of you in this room as well, it changed the course of my life. I can see how it directly led to those still special moments I have now where I'm sitting at a new blank file in my code editor, knowing almost anything is possible with software.
This interconnected world was possible because the people building it saw the importance of developing protocols and standards that would be flexible enough to adapt to changing needs but also clear and concrete enough to implement easily on many different kinds of systems. The result was things like TCP/IP, email delivery, web browsing and domain names. These systems and standards are not perfect and we'd probably do it a little differently today if we had the chance, but they were robust enough to serve as a foundation for decades of evolving the modern Internet. And perhaps most importantly, they allowed the rest of us to create things that couldn't have been predicted all those years ago.
What I see in attempts to build tools and systems today, then, boggles my mind. Instead of learning from the lessons and benefits of using interoperable, flexible standards that help ensure wide adoption and future evolution, people strike out on their own, either creating new "standards" on a whim or just altogether abandoning the idea of making their thing talk to any other thing.

I think we all know that frustrating feeling when there are two things we want to talk to each other and they just...don't. Whether it's the different shapes of our USB ports or trying to find a meeting time that works across several individual calendars, we hit these bits of friction multiple times per day every day. It may especially be true for people who work in the world of software and technology, but I suspect we are more equipped than others to understand the problem and pursue a solution. The rest of the world is left to Google "how do I make my ___ talk to my ___" and hope there's an easy answer. Or they just give up. And if you've ever been the tech support person to a friend or family member who is trying to import, export, merge, segment, chart, integrate or upgrade, you know how frustrating it can be.
Everywhere we look, there are closed systems that don't talk to each other and that don't give us full ownership and control of our data. And it's not just because they forgot; I think about Facebook and Instagram shutting down APIs. Twitter removing RSS feeds. Wix prohibiting exports of your site content. Standards that aren't really standards at all. Tools we depend on without any real control or ownership. Services that can go away at any time, taking our personal data and creations along with them.
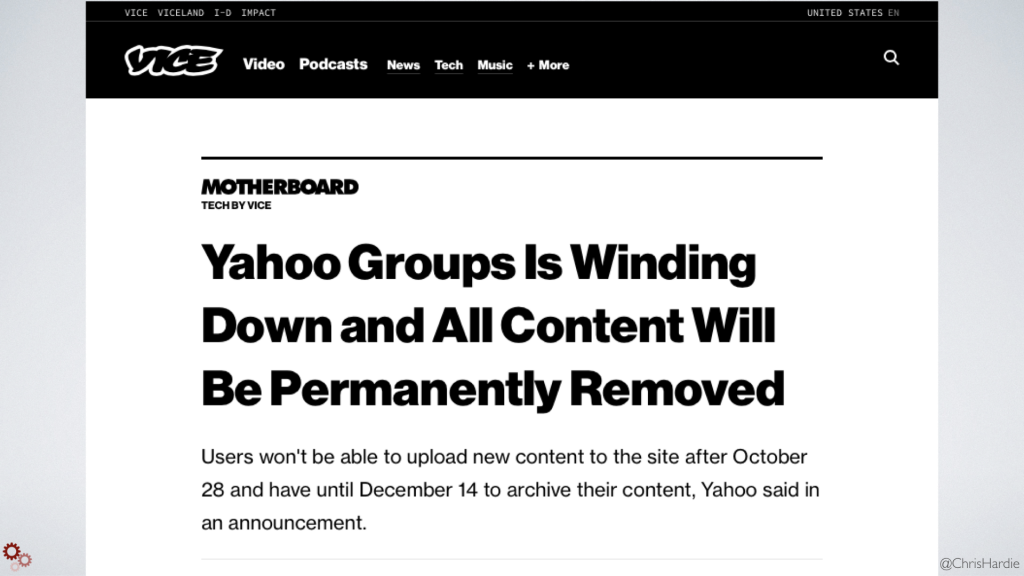
Here's Yahoo announcing just last week that they were shutting down Yahoo Groups and that the content and conversations built up by contributors over two decades would be permanently removed. It's hard to watch.

If you haven't heard the term "open web" before, it's one answer to this situation. As Mark Surman, Executive Director of the Mozilla Foundation described it, "An open web is a web by and for all its users, not select gatekeepers or governments." It's open source, open standards, free expression, digital inclusion, and ownership and control of what we do online. Without these things, innovation and competition stagnate and silos of knowledge and experience emerge. Without these things, power is concentrated in the hands of a few and under-represented groups can be left out entirely. But when we get it right, it encourages those same things the original web was built for: a level playing field for collaboration, dialog, sharing and learning.
We have a long way to go to bring everyone back to a truly open web. It involves education, advocacy and building open tools that also happen to be the best tools. And sometimes it's about creating some little bits of glue that bridge the gap between two systems in a way that improves our lives or just simplifies things.

I want to show you some examples of those kinds of glue as a way of illustrating how our tools could and should be able talk to each other, some of the stumbling blocks I've encountered in building them, and perhaps give you some ideas for glue you could add to your own life and work.
I have a friend where I live who was working on a project to interview people in my city for StoryCorps, which if you're not familiar collects, organizes, preserves and shares stories from people across the country.
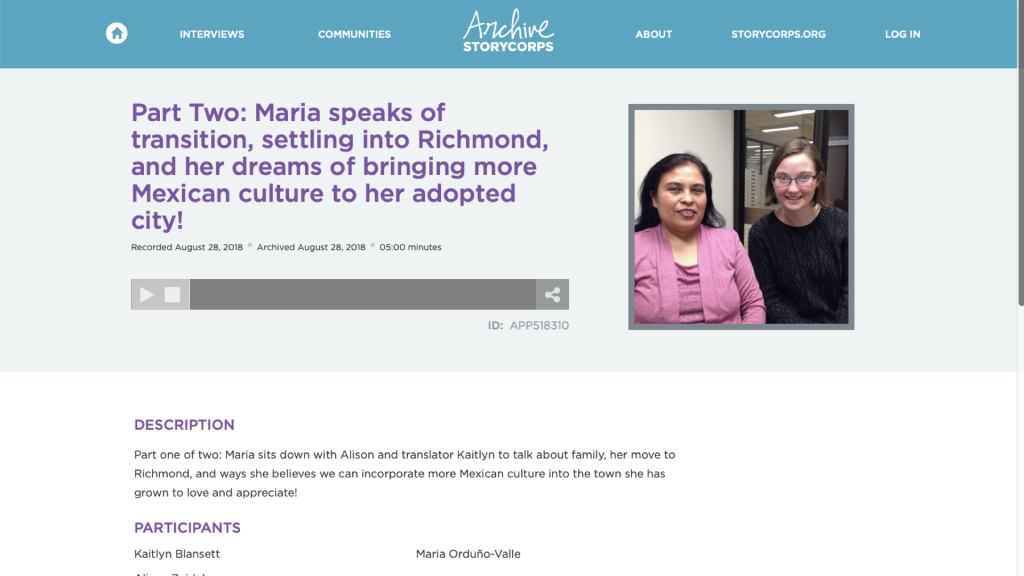
It's an amazing project. She was creating these excellent snapshots of people's lives, documenting their hopes and dreams, and I wanted to know about it as soon as a new local interview was posted on the StoryCorps archive website. But when I searched for my city and viewed the results, I didn't see any way to subscribe. There was no "email signup for new results in this search" feature. There was no RSS feed. Sure, I could have bookmarked the results link and come back to it on a daily basis, but that doesn't feel scalable or sustainable.
Then I noticed that the StoryCorps archive site was built using WordPress.
This was a happy moment because I know WordPress really well, especially given that I work for Automattic, the company behind WordPress.com and a bunch of other awesome WordPress-related tools and services. And I knew that modern WordPress has a REST API built in right out of the box. If you're not already familiar, an API is basically just a way for one piece of software to make its information and functionality available in a structured way so it can be used by another piece of software.

So I saw that the awesome folks who had built the StoryCorps site had created a WordPress post type for the interviews there, and that they were properly tagged and categorized in ways that included city and state, and that all of this information was available via the WordPress API! Yes!

After poking around different API results to understand just what the different fields were and what would be acceptable search criteria, I wrote a short script to make a request to that API and turn the results into an RSS feed for myself.
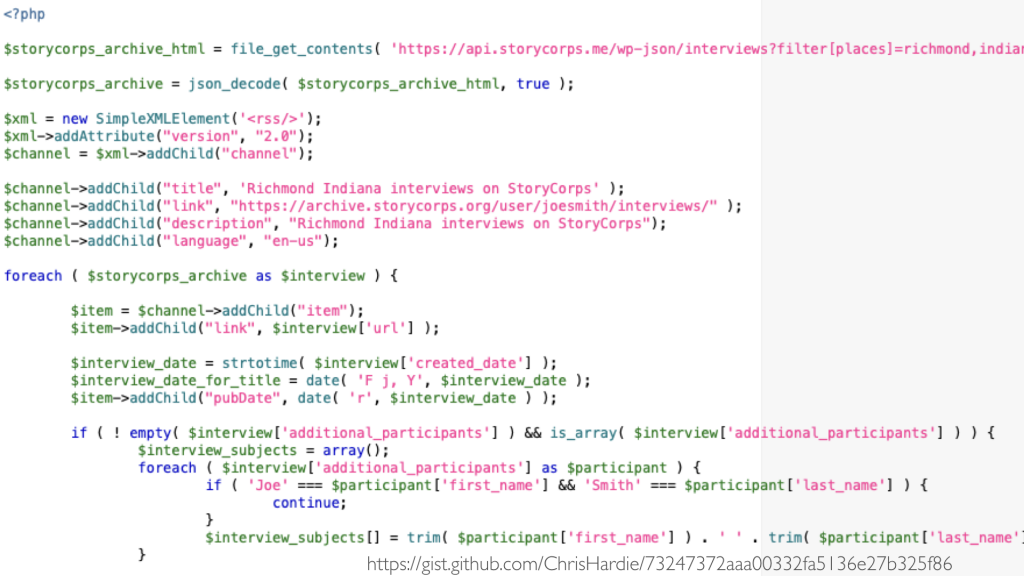
If you're not already familiar, RSS is yet another way to take the information found on a website or some other resource and make it available in a structured way that can be read by other software, including RSS readers like Feedly or the now-retired Google Reader. So I put that script on a server I run and set it to run on a regular basis via cron, outputting the RSS feed to a publicly accessible URL. From there, I set up Feedly to subscribe to that feed, and I could then know through my regular use of Feedly when a new StoryCorps interview in my town was available. Yay!
So creating a feed of structured data from an existing feed of structured data was pretty straightforward, and not every bit of glue will be this simple as we'll see. But it was a fast way to make sure I didn't miss an amazing collection of stories in my community, so well worth it, right?
And then, this happened.
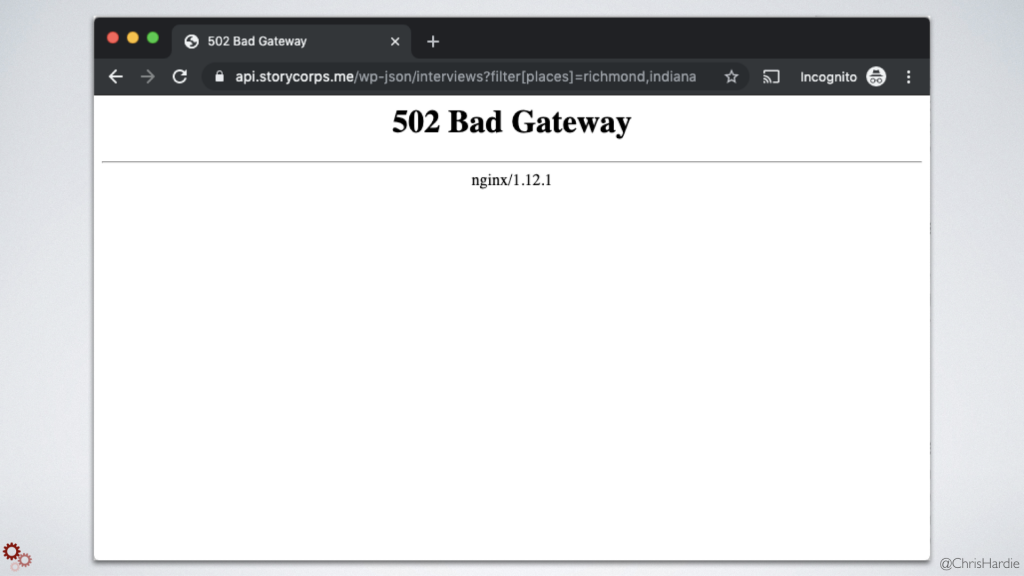
At some point in the last few months, my script stopped being able to query the StoryCorps WordPess API endpoint. The StoryCorp web server returned a "502 Bad Gateway" error message. But the server only returned that result when you searched for my particular query of my city and state name. Queries for cities down the road in Ohio? Came back fine. Yes, some person or piece of software watching over the StoryCorps webserver probably noticed an inordinate amount of API requests for Richmond, Indiana and they decided the best course of action was to block those requests. I was making the request less than 50 times per day, but apparently that was enough.
That's okay, it's their site to manage. But for me it underscores the fragility of these homegrown bits of glue. A tool doing something as simple as querying an API is still subject to breakage when the site owner changes how the API works, upgrades or replaces the site, or just decides they don't want you doing that any more. This is why it's so essential for site developers and site owners to offer official, reliable, long-term structured access to the content and functionality on their sites. If you just optimize for people visiting through a web browser, you're cutting off all sorts of as yet unimagined ways that people could build on what you've created.
You can see this fragility in action among people who have tried to provide structured access to Instagram profiles.
If you want to visit the Instagram of your friends, family or colleagues, really the only official way to do it is through the Instagram app or website. But if you don't want to spend time visiting Instagram just to see if there's something new there from the people you care about, you might search for another solution.
I went on this search. I inspected the HTML source of the Instagram profile page, found the bit of JSON data where the actual image feed was being stored, and wrote a short PHP script to fetch that JSON and turn it into an RSS feed.
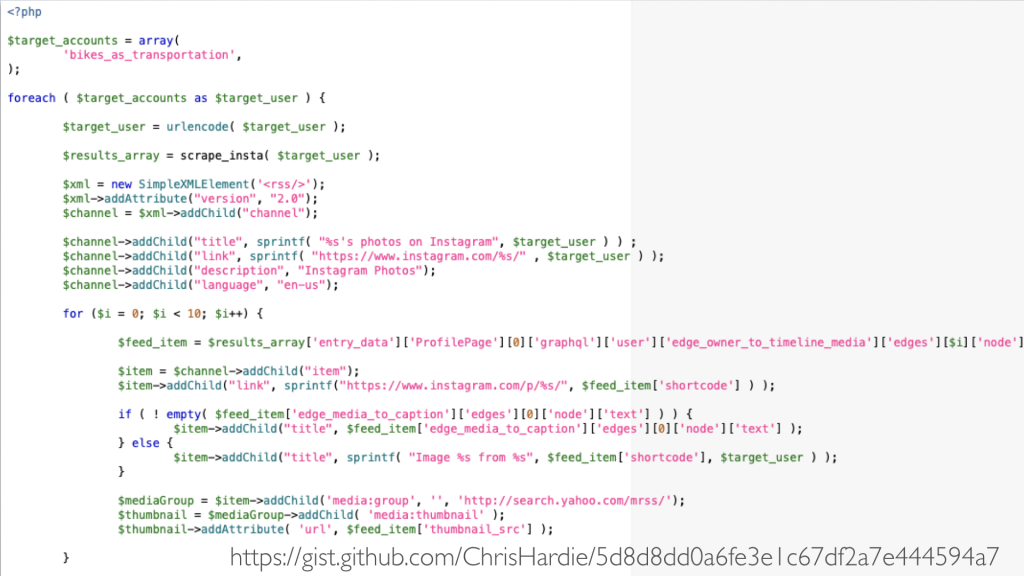
Again I put it on a server I own and again set it up to run on a regular basis. It worked great for a month or two, and then Instagram slightly changed the HTML code of the profile page. I tweaked my script, and it worked for a few more months. And then Instagram made another change and I haven't had the time to track down exactly what broke.
I wasn't the only one. The service QueryFeed used to offer a free service converting Instagram profiles into RSS feeds too, and then they realized how much time it was going to take to maintain that every time Instagram changes things, and now it's understandably a paid feature.
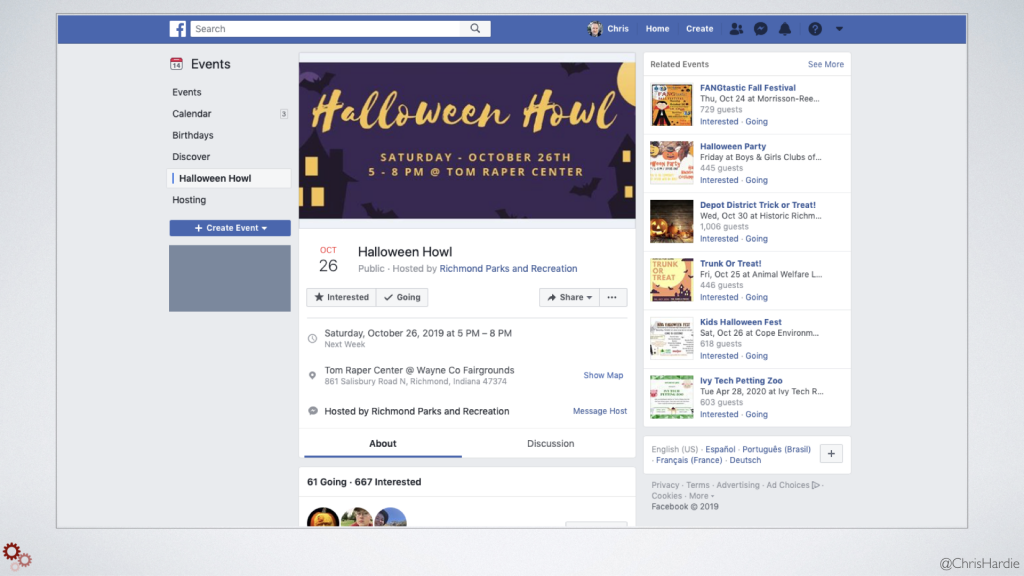
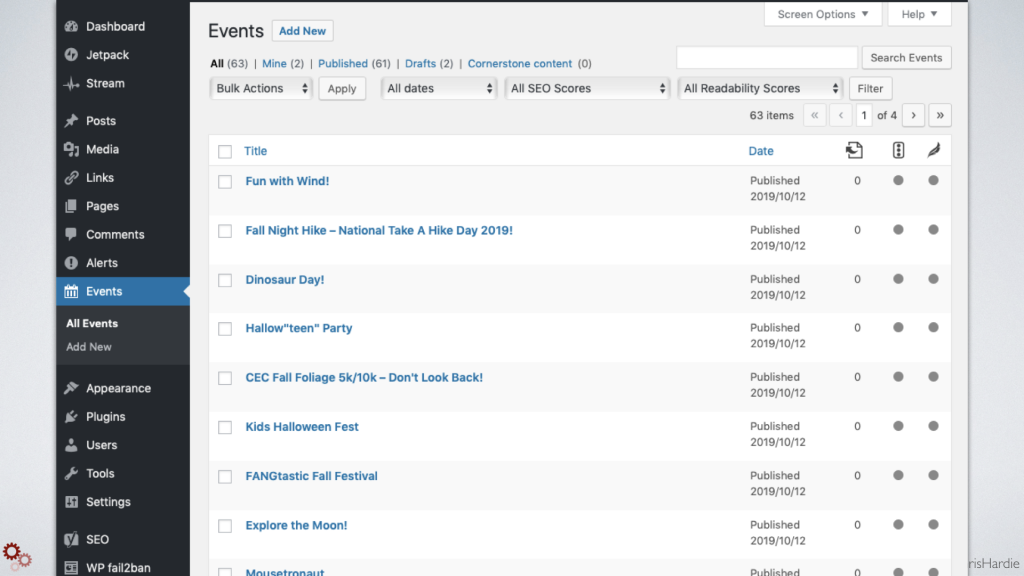
Let's return to the problem of bringing Facebook events into a website or some other system. There is no public API any more, there is no RSS feed, and Facebook event pages are very difficult to scrape in traditional ways because of how they are rendered. I spent some time examining that setup using the Inspector in my browser.
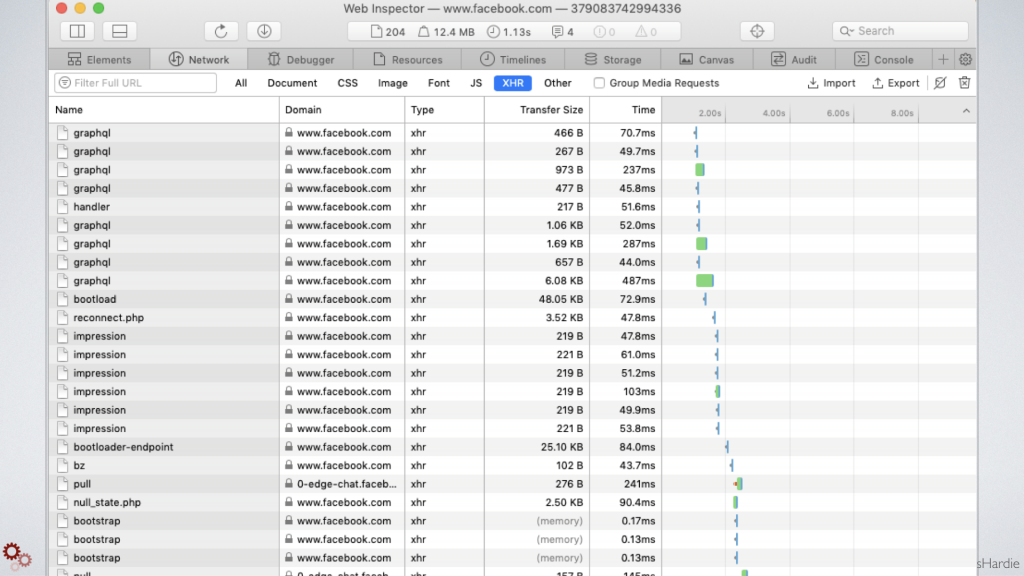
Inspectors in modern browsers like Chrome, Safari and Firefox allow you to do lots of things, and one of those things is to look at the asynchronous requests between what's usually a Javascript-powered front-end application and the data it's accessing from the server. You'll usually see it labeled as XHR, which stands for XML HTTP Request.
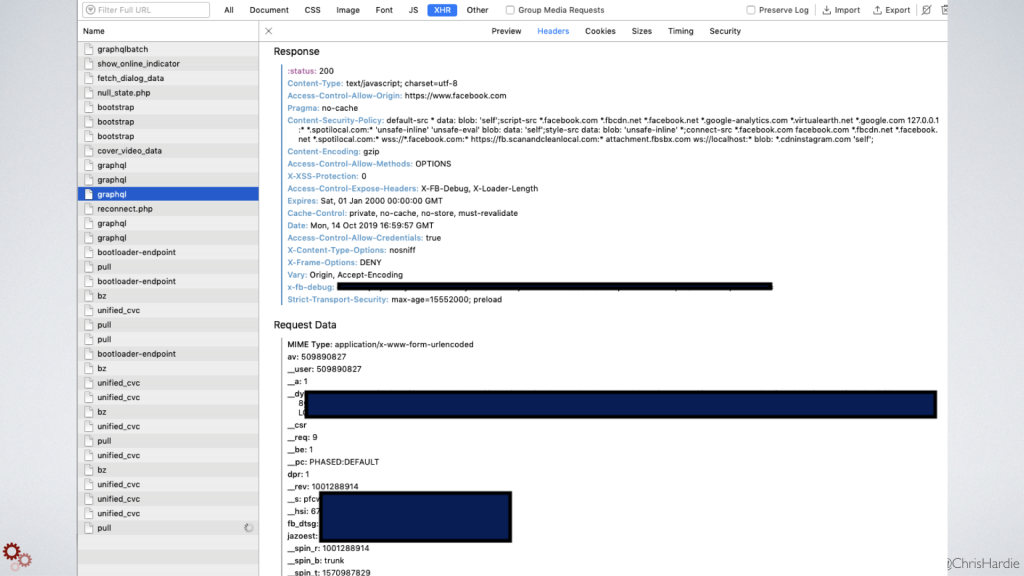
And if you look at these requests and poke around a bit, you can usually figure out what internal API endpoint is being called to populate the page. In the case of a single Facebook page's events, I found that the Facebook Javascript was talking to their GraphQL endpoint and in particular requesting this function called "Page Events Tab Upcoming Events Card Renderer Query." There was a long list of other query parameters the browser was sending, about 16, and so through the process of elimination I narrowed it down to the 12 parameters that were actually required.
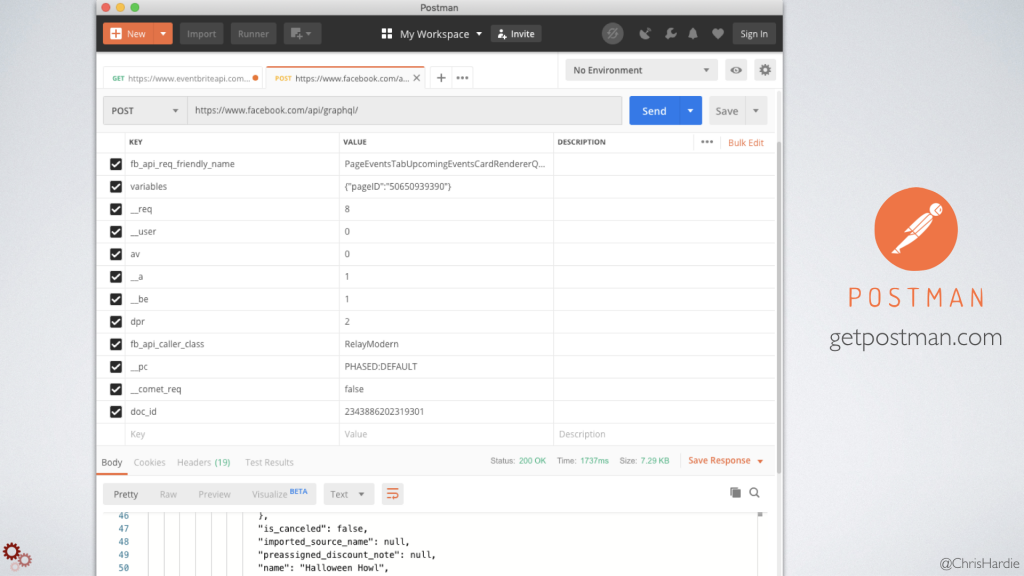
I did this, by the way, using Postman, which is an application available for Windows, Linux and Mac that makes it easy to work with API endpoints and all the pieces that go with that - query parameters, authentication, displaying results. It's stuff that can be a real headache to do on the command line or to whip up a test script for every time, and it's saved me hours of time when I dive into something like this.
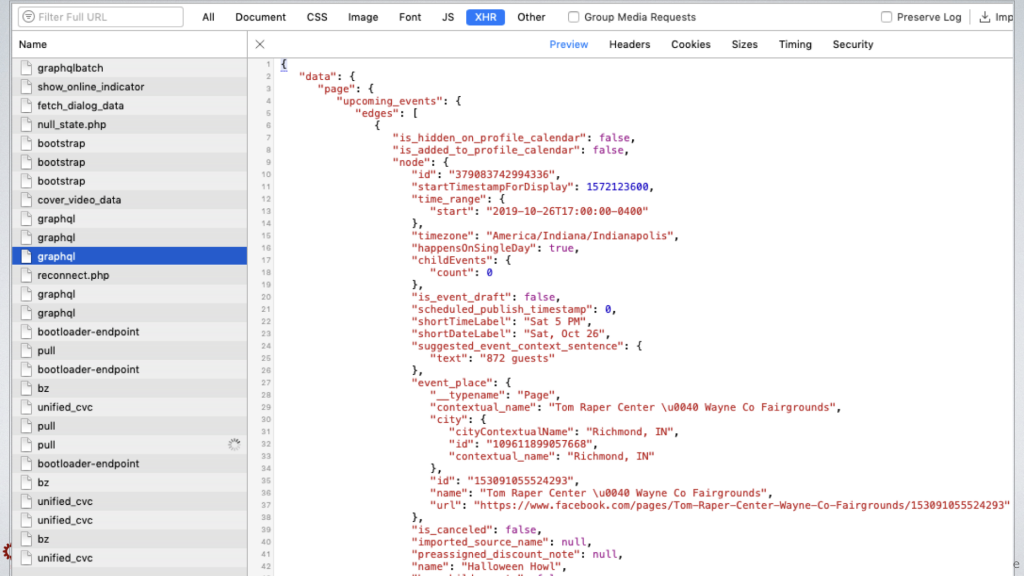
So I got to the point where I could reliably retrieve upcoming events for a given Facebook Page ID, and I went ahead and created a proof of concept script that would take an array of Facebook page IDs and put all of the upcoming events for them in a data structure I could work with.
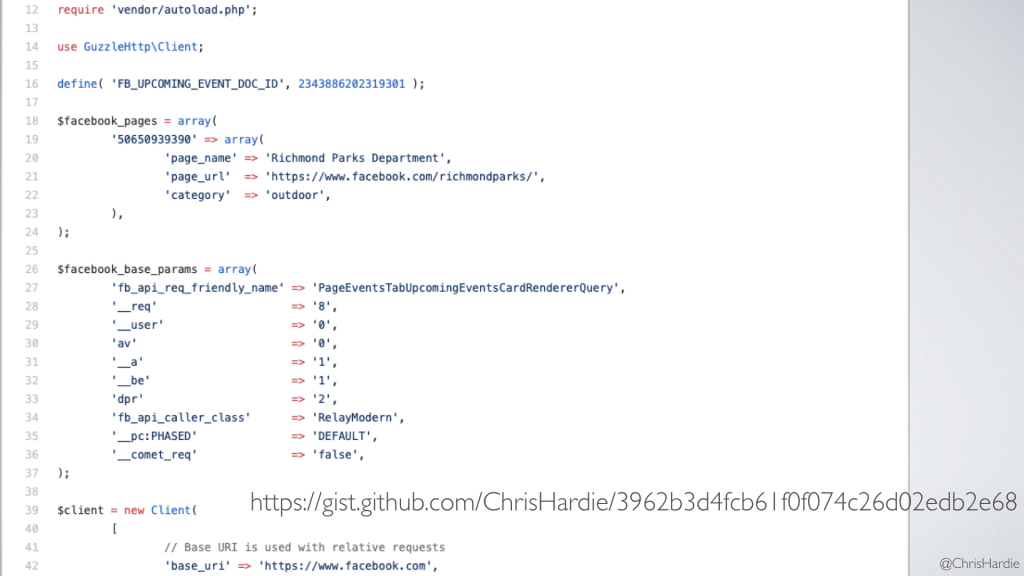
I also experimented with turning this into a WordPress plugin and having that same routine run on a schedule within WordPress, inserting the events it finds as WordPress posts in a custom post type.
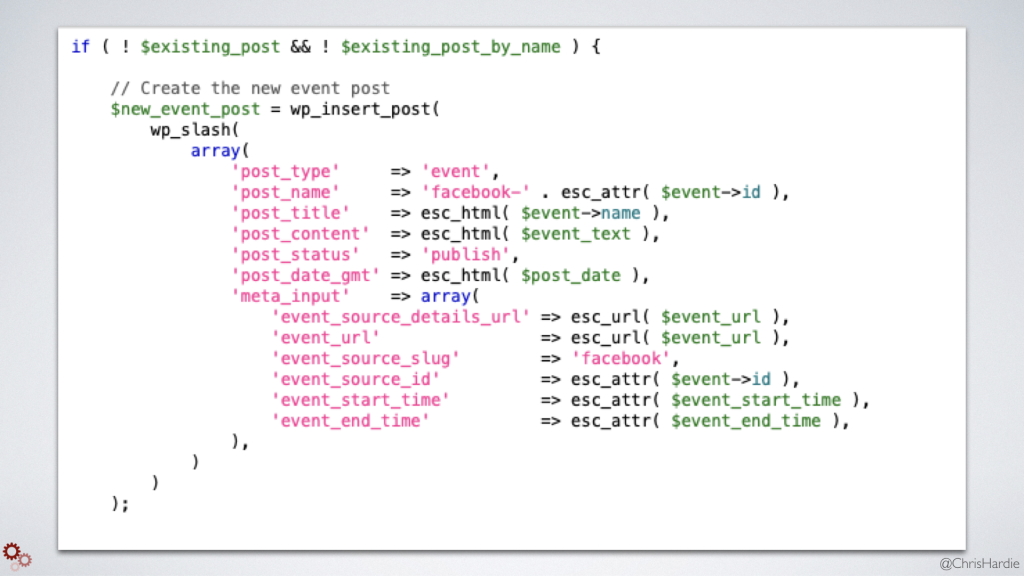
WordPress makes this kind of thing really easy, and then I can seamlessly integrate those events into the rest of my content and website.
Now, does Facebook care if we access event data in this way? Yes, yes they do. Their terms of service about Automated Data Collection explicitly states that if you try to extract data from the Facebook platform in an automated way, they can ban you forever. But more likely than anything is that they will change the way their platform works to make this kind of data retrieval even more difficult.
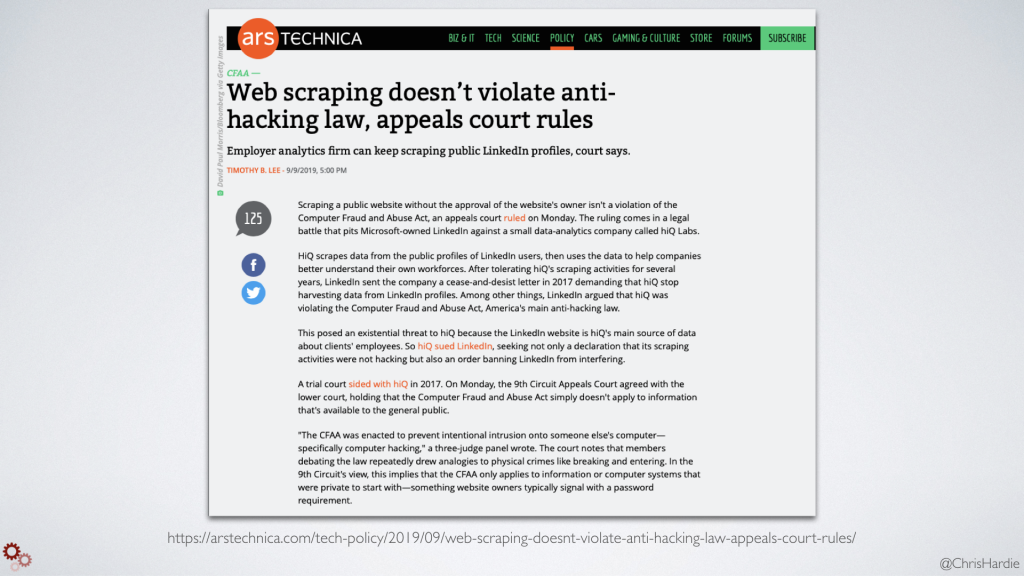
I think there's hope for some shifting expectations about what's considered fair here. A U.S. appeals court ruled just last month that web scraping does not constitute illegal activity, and went so far as to acknowledge that if a scraper is retrieving publicly available data owned not by the platform but by its users, the scraping can't be blocked.
In the case of Facebook event data, it's worth noting again that we're talking about publicly available information shared by organizations that want it to get more exposure online about events that they want the public to attend. Restricting access to it seems like such a shame to me.
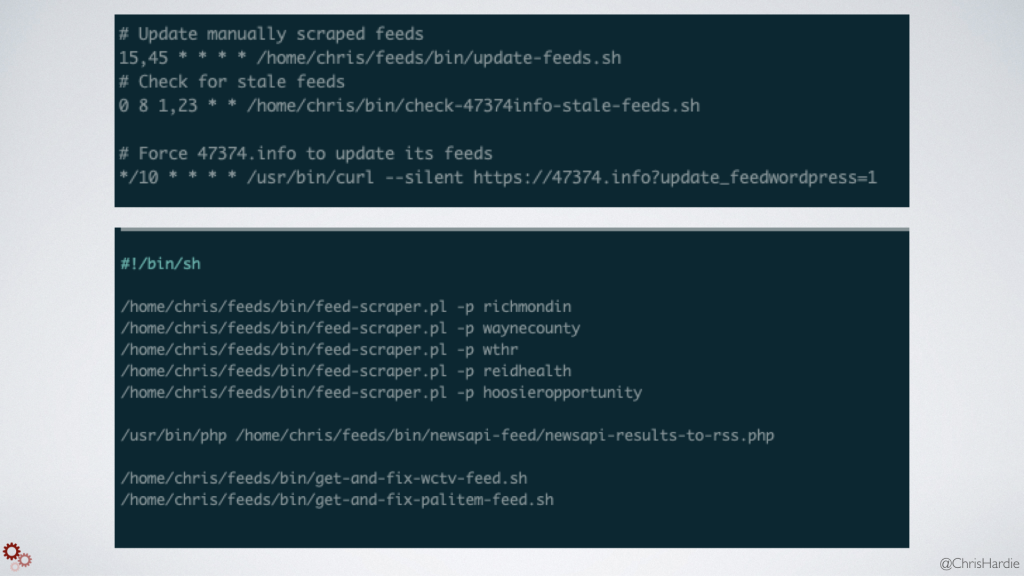
I personally have about 7 different sources where all day long I'm scraping the HTML source, looking for updates and turning them into RSS feeds. I have two more sources where they provide an RSS feed, but don't handle character encoding properly, and so I've created scripts that pull down the feed, fix the character issues, and then re-publish them so they'll work in RSS readers.

It's all very fragile and yet I find it strangely rewarding and interesting to work on.
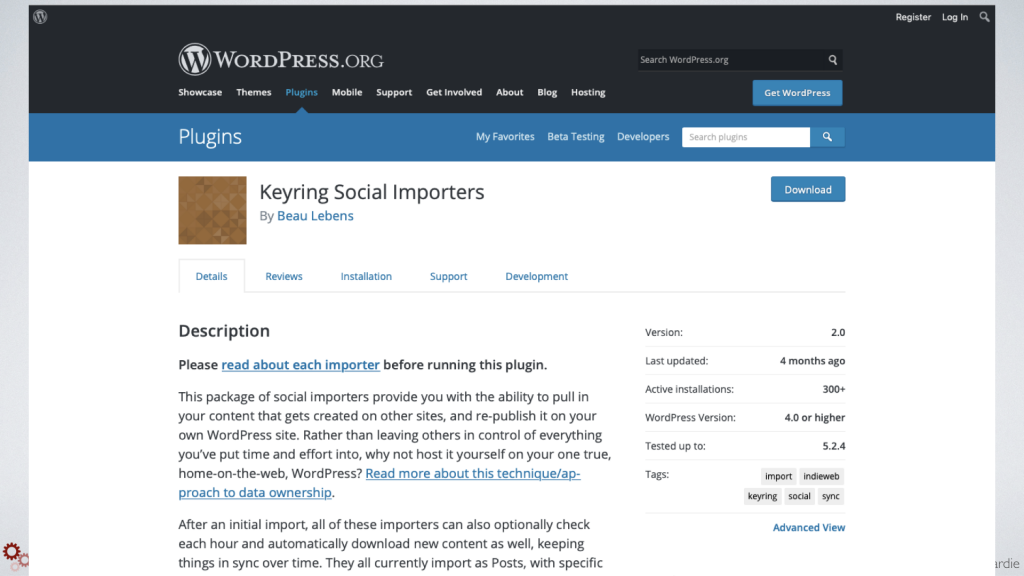
If you'd really like to get into pulling content together from across the web, especially for your own disparate accounts, there's a cool WordPress plugin called Keyring Social Importers by my colleague Beau Lebens.
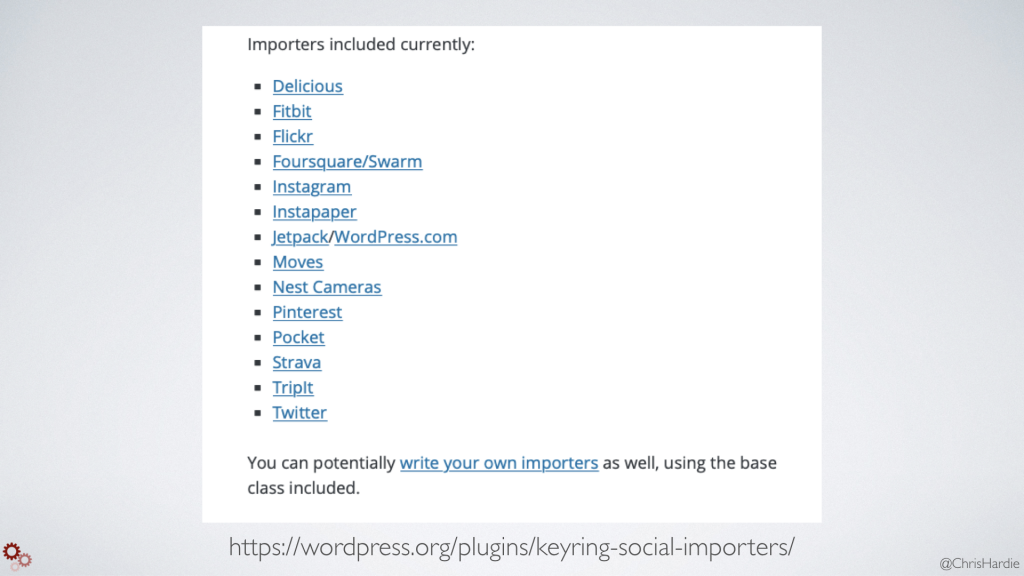
It allows you to authorize access to different accounts like Instagram, Flickr, Twitter, Pinterest, Strava, Fitbit, and then it will import all of your data from those accounts into WordPress posts. You can do it on a one-time basis or you can poll continuously for new updates and import them as they appear.
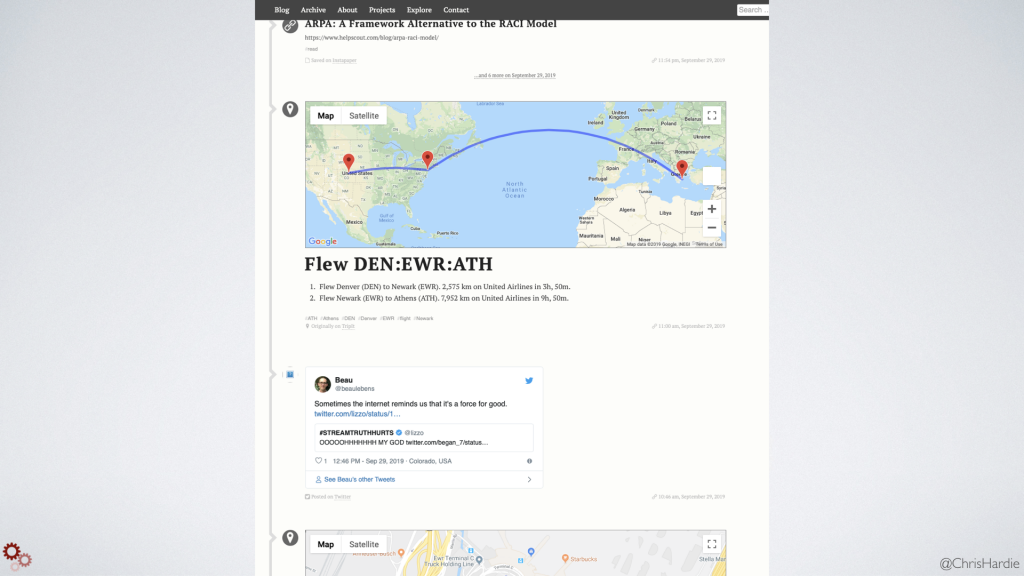
The end result is a really cool stream of all your activity online, and here's Beau's website illustrating that. Photos posted, Tweets tweeted, trips taken, places you've checked in at, runs that you run, and so on. And it's not just a title and a graphic, the plugin is bringing in as much meta data as it can scoop up from the APIs that these services offer and storing them in post meta fields within WordPress. So you can start to imagine some of the cool applications you could build on top of that using the WordPress API and having all of that information in one place. It's a nice bonus that if any of those services ever go away or change the way they operate for the worse, you don't have to worry about how to export and archive your content there; it's already on a site you fully own and control.

Next up, let's talk about webhooks.
While RSS feeds and APIs are great for polling a resource or website to see if there are any changes, sometimes you want something that's more real-time and triggered by an event or action on the resource you care about. That's where webhooks come in.
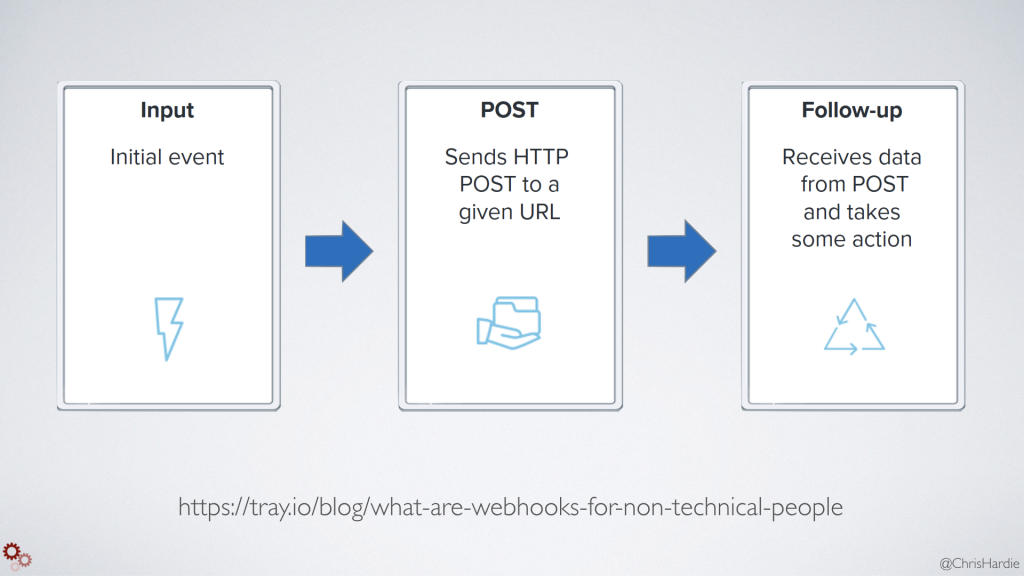
A webhook is typically just asking the website or tool you care about to run one teeny tiny HTTP request at the very end of the event you're tracking. Whether it's publishing a blog post, adding an entry to a database, committing some code, or turning on your internet-connected lamp, you can use webhooks to build tools that do something else when those actions happen, without asking the original service or tool to add any other features.
How many of you here have used services like If This Then That or Zapier? Most of the functionality of those tools are provided through webhooks or an equivalent. A site, service or device does something and sends a webhook request to IFTTT, and then IFTTT uses a recipe you've set up to send another webhook request out to another site, service or device to trigger the dependent action.
They're great, and they have on their own opened up tons of possibilities for gluing together disparate systems. When I want my SmartThings smart home hub to post something really important to Twitter I can do that with IFTTT.

But when I started looking in to running my own webhook server, I realized that I could support basically any combination of services that have any kind of webhook and API support. I found an awesome open source webhook server project and got it up and running on my own server pretty quickly.
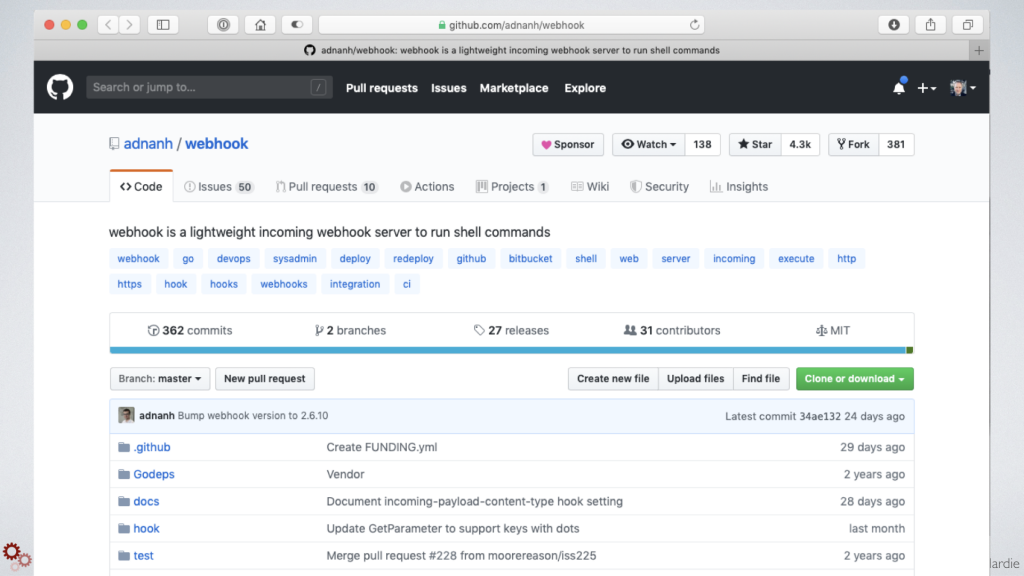
From there I can start to build applications that do exactly what I want without giving up any additional ownership or privacy of my personal data.

When I merge some code to one of my private repositories in Bitbucket, it calls my webhook server and runs a script that does a git pull so the code goes into production. If you're familiar with services like DeployHQ or Deploybot, it's the same workflow.

When my car stops or starts a drive, the data from my Automatic car adapter is pushed to my webhook server where I can process it and perform certain actions, like sending myself a push notification reminder about something I need to do in or near a certain location.

And SmartThings can be set up to post all device events to my webhook server, so I can log and act on them in ways that aren't a part of the default SmartThings service.
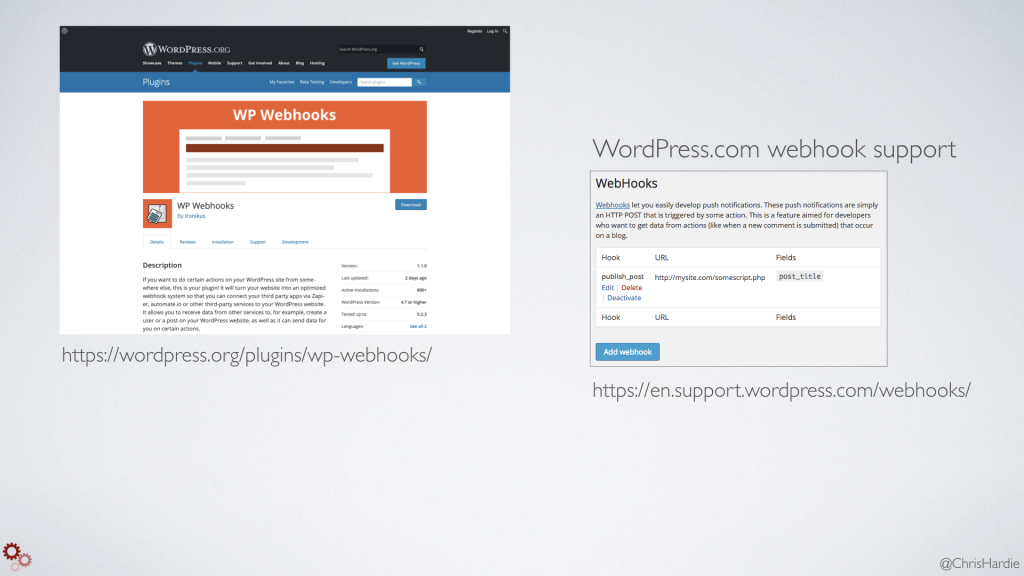
There are WordPress plugins for both sending and receiving webhooks on your WordPress site when certain actions happen. So you can think about having something happen elsewhere on the Internet when a new post or page is published, or you could have something happen on your WordPress website in response to say, a device changes its state or some other non-WordPress site being changed.
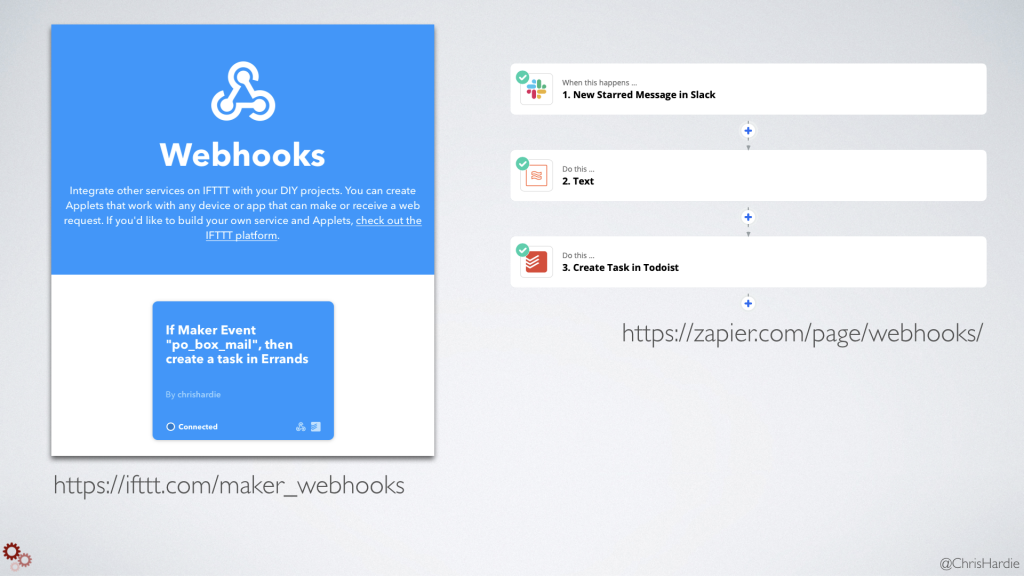
You don't have to run your own webhook server. IFTTT and Zapier support webhooks too. For each one, you can set them up to receive or send webhooks as one components of any recipe or Zap you create. This immediately gives you access to integrate hundreds of services with your own custom code.

You can imagine these kinds of workflows playing out across almost any system or process you work with. They present really cool possibilities for automation, audit logging, and generally just unlocking your data and making systems talk to each other.
I've covered a lot of ground here, and I know that not all of these examples will apply to your work, life or interests. But I hope that I've convinced you to think more about when and how the tools we use do and don't talk to each other.

And I want to make a plea that if you are someone involved in building software or tools that other people use, you take the time to consider including components that support more openness and access.

Make available a robust, well documented API that allows anyone to interact with all of the core data and transactions managed by the resource you provide. Make sure it's as fully-supported and well-maintained as every other piece of software you ship. Bonus points if you provide an API testing console, example client libraries and example queries and responses.
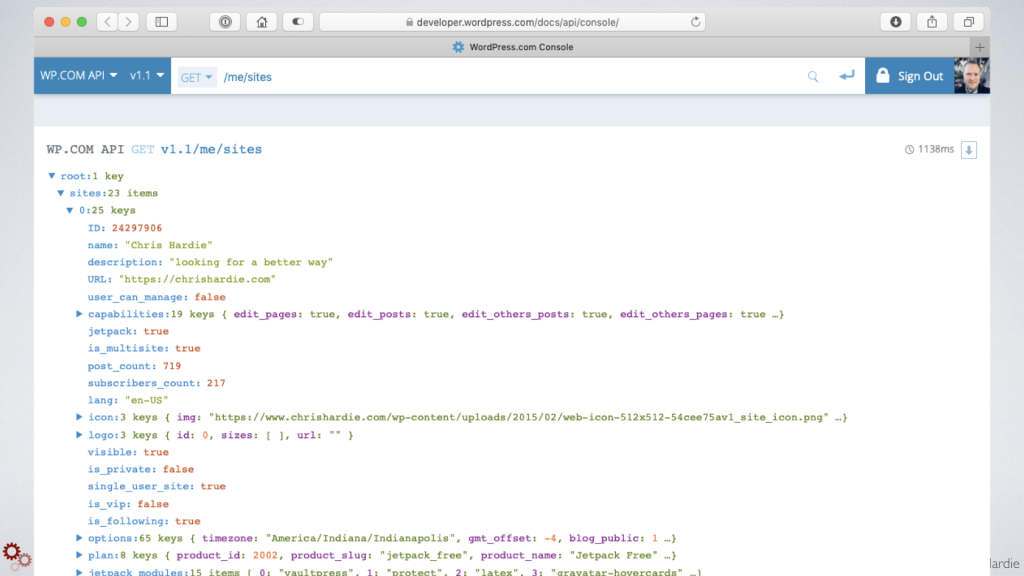
Here's the WordPress.com API developer console where we let people explore using both the WordPress.com API and the core WordPress API for any Jetpack-connected site they might own to retrieve content and manipulate their sites. It's powerful and some people are building really great applications on top of it.

Second, please make available some kind of structured data feeds for your content. Whether it's RSS, JSON or something else, give your users the opportunity to consume that content in the tools of their choosing. Even if you have to insert ads. Even if it's private or paid content. For private content you can use a unique hash in the RSS feed URL to limit and track public redistribution. And make sure the link to the feed is visible and easily findable on your site.
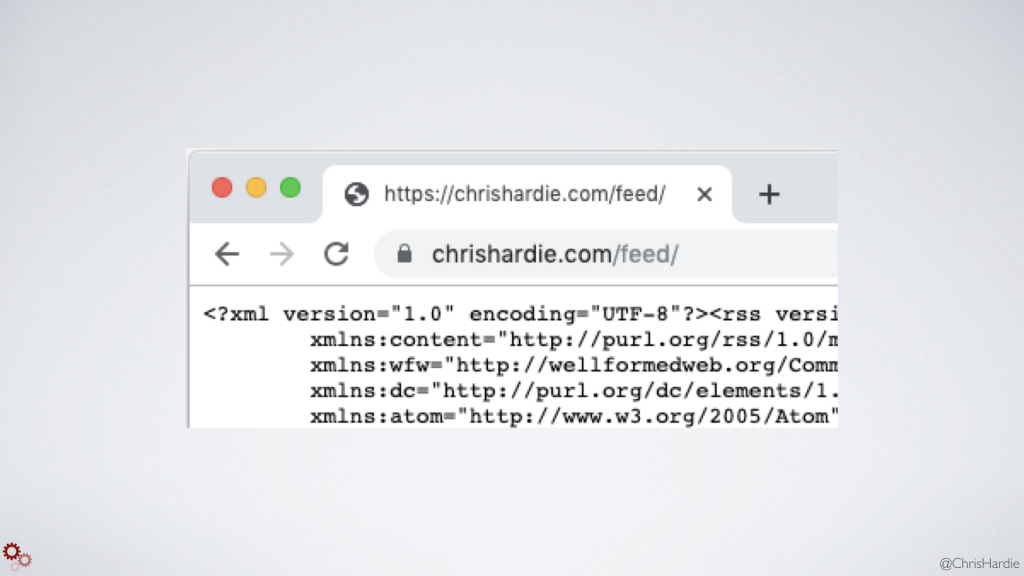
I think one of the things WordPress as a widely-used tool, and similar CMSes too, have done for the open web is to make RSS feeds available right out of the box when you spin up a new site. They can be filtered, customized or even turned off, but the default of starting with a feed in place is a good thing.

Third, please make sure your users can easily initiate a full export of their data on your site. Make sure it's in a commonly used format that could be easily and programmatically converted to another format. It doesn't matter if you can't imagine how they might use it or if they'll ever need it at all. Having the option to download what they've created and tinker with it or store it away for safekeeping promotes a sense that they are building something that can grow and evolve for the long run instead of contributing to a closed system that might go away and take their content with it.

Provide documentation and technical specs. Even if your service or tool is incredibly simple and self-explanatory, documenting what it does, how it does it, and even how you made it can be so useful to people who want to use that service and build on top of what you're offering. Try to think in terms of launching a community or ecosystem that thrives because the thing you're offering is so transparently wonderful that people just can't help themselves but add on to it.

If you can, make the source available. Even if it's ugly, even if it's broken in some places, even if a big refactor is just around the corner. Sharing what you can here increases the chances that people will build other systems that talk to it, and invest their time and energy into making your thing better.

Now, if you're not someone developing tools and software, I still encourage you to think about these things. Look for these things when you're considering services to sign up for. Ask questions before you hand over money - where's your API? Are there RSS feeds? How do I do an export? You can learn a lot about the approach and culture behind the tool you're about to invest your time in, and it might help you see your options a little differently.

A lot of what I've said today is about how closed off and frustrating systems can be. But I think there's also a lot of hope out there for pursuing a more open web. There's a growing recognition that owning our homes on the web and having control of what we publish and what we see is a core part of online freedom. There's a resurgence of interest in blogging or individual publishing as an alternative to handing over our thoughts and ideas to someone else's proprietary platform and hoping they get traction. You may have heard that my employer Automattic just invested in buying Tumblr so that we could preserve and grow that amazing community of bloggers and publishers. Podcasting is a tool and technology, built on RSS feeds by the way, that encourages easy sharing of an amazing range of audio content regardless of what tool you use to listen to it. And then you have folks doing the kind of tinkering I've shown today, seeing how systems could be made to open up just a little bit, talk to each other just a little bit more than they already do.
I think if we expect and pursue that kind of openness on the web, we'll see good things happen, and we'll again be honoring the spirit in which the original web and internet were able to exist and thrive. Thank you.

You can download the full slide deck as a PDF.
 I’m a journalist, publisher, software developer and entrepreneur with experience as a founder and organizational leader. Work with me or learn more about me.
I’m a journalist, publisher, software developer and entrepreneur with experience as a founder and organizational leader. Work with me or learn more about me.
One thought on “Slides and links from my php[world] talk”