Almost exactly a year ago, I shared my tool and process for moving a Flickr-hosted photo collection to a WordPress-powered photo website. That tool has been used by a few folks now and I'm so glad it was helpful.
The thing that I hadn't done yet, but now have and detail in this follow-up post, is to create an automated way to clean up references to Flickr-hosted photos that exist in an existing WordPress website or blog. Without this critical final step, one could have a lot of historical content that still references Flickr-hosted photos instead of the version being hosted on your shiny new WordPress-powered photo site.
So here's how I did it. As with my previous post, this information is geared toward a technical audience that is comfortable with the command line and possibly modifying PHP code to suit their own purposes.
Method
I thought about a couple of different ways I could handle this "find and replace" operation.
With 13 years of blog posts, many of which contain references to Flickr photos in some form, making the changes manually was not an option.
I thought about continuing to iterate on my existing PHP command line tool that takes the exported Flickr dataset and generates a WordPress import, which would mean creating some kind of lookup data file where a find-replace command would use the Flickr photo URL to find the new WordPress-hosted photo URL. But when I saw all of the different ways I had embedded Flickr photos in my blog post content:
- on a line by itself for oembed rendering
- as simple links to a Flickr photo page
- as
<a>plus<img>tag groups that displayed the images full size inline with a link - as
<img>tag groups that displayed the images at various smaller sizes, aligned left or right
I realized that I would need to be able to lookup the proper image URL for each display scenario. And given that my WordPress-powered photo site generated different image sizes (and that some of these had changed since the original data migration), that was not going to be simple. No one-size-fits-all substitution would work.
The good news is that WordPress easily supports building a custom REST API endpoint that would support a dynamic lookup of the information I needed on the photo site, for use on any site where I was finding-replacing content. Once I realized I could decouple those operations, it was clear how to proceed.
Creating a "Find by Flickr URL" API Endpoint
The first step, then, was to create a REST API endpoint on my WordPress-powered photo site that would allow me to specify the original Flickr photo URL and find the related WordPress post that had been generated during the migration process.
If you look at the code of the original migration tool, you'll note that for each WordPress post it creates, it adds a post meta field _flickr_photopage where it stores the URL of the Flickr-hosted photo. That usually looks something like https://www.flickr.com/photos/myflickrusername/123456789/. We can use that post meta field to do a simple lookup of the equivalent WordPress post object.
Since I want to be able to retrieve an image URL at a specific size so that I'm not embedding full size, large image files in posts that only need, say, the 300 pixel wide version, I also needed to accept width and height parameters, and then do a lookup of the related attachment file URL in WordPress.
Here's the class that I created to do all of this. If you use it, you'll need to customize a few things, including the Flickr username.
With that class loaded into my WordPress photo site's theme or in a plugin, now I have access to this kind of API call:
https://my-wp-photo-website.com/wp-json/myphotos/v1/find-by-flickr-url/?flickr-url=https://www.flickr.com/photos/myflickrusername/123456789/
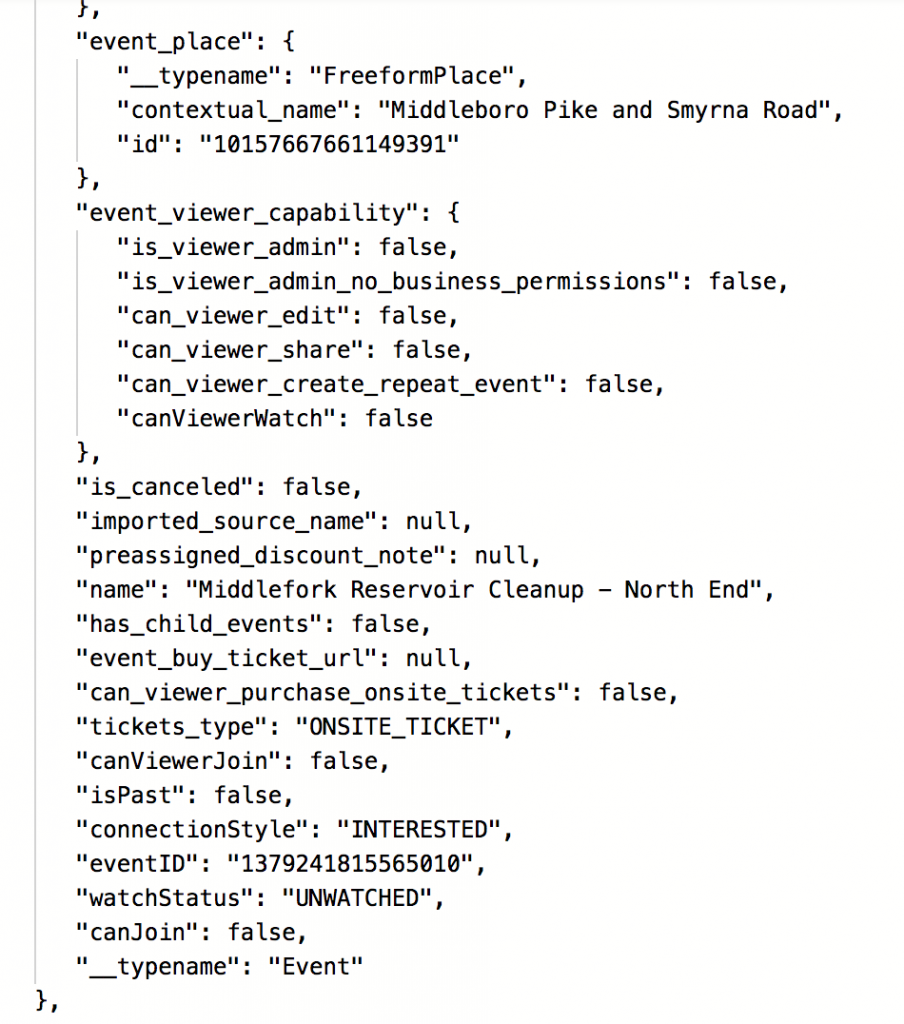
And the returned JSON response of that kind of API call would look something like this:
{
result: "found",
post_id: 2425,
permalink: "https://photos.chrishardie.com/2014/08/updesk-setup/",
thumbnail_id: 5424,
thumbnail_url: "https://photos.chrishardie.com/wp-content/uploads/2014/08/15130177147_75d885dc2a_o.jpg",
thumbnail_width: 2448,
thumbnail_height: 3264
}
Nice! Now I have the permalink of the photo post that replaces the original Flickr photo page, the URL of the image media file I can use in an <img> tag, and some other meta info if I need it.
The Find-and-Replace WP CLI Plugin
Now, it's time to use that API endpoint in a big find-replace operation.
The clear choice was to make a WP CLI command that could be used to run this on the command line, where I could log and review warnings and errors and have better memory management.
In creating this command, I used this general approach:
- Get all the posts in the WordPress database that mentioned a Flickr URL with my username in it
- For each post found, look for specific kinds of Flickr link and image references that need to be replaced
- Extract the original Flickr photo page URL from those references
- Use the API endpoint created above to look up the corresponding information on the photo site
- Update the post content with the information retrieved from the API
It sounds fairly simple, but I ran into several challenges and opportunities for optimization:
- Not only were there references to the Flickr URL structure above, there were variations to consider such as the internal version of my Flickr user account ID that was in wider use years ago, or the
flic.krshortened version of their domain. - The API lookups could generate a lot of activity on my photo site, so I added some caching since those responses should rarely be changing.
- I found some photos that I had apparently set to "private" or "contacts only" on Flickr but had left referenced in my blog posts, so I had to manually address those.
- My Flickr-to-WordPress migration tool didn't handle Flickr "sets" (although it preserved and stored the data needed to handle the), so I had to redirect those references.
- I had to make sure not to replace Flickr references to other people's photos.
- Flickr varied its use of
httpversushttpsin different embed code it generated over the years.
In the end, I had a working plugin that could do a dry-run operation to see what it was going to change, and then do a "for real" run to actually update the posts as stored in the database.
$ wp flickr-fixer fix-refs --dry_run=false Getting all posts containing Flickr references... Found 203 posts to process. Success: 621 replacement(s) made across all posts
With the API lookup cache primed, on my site it only took a minute or two to run. YAY!
You can see the final plugin code here.
(If you use it, you'll need to find/replace my Flickr username and a few other hardcoded references accordingly.)
Lessons Learned
When I think about the time I put in to first creating the original Flickr-to-WordPress migration tool, and then the time put into this content cleanup tool, it turns out it was a non-trivial project. But it always felt like the right thing to do, since once I was moved fully into WordPress I would have absolute control over my photo collection without depending on the changing services or business model of Flickr or anyone else.
It also highlights a few important lessons for migrations and owning your data online:
- Try to be consistent in the ways you reference third-party tools and services in your content or workflows. If you have a bunch of variations and inconsistencies in place, any future move to another tool is going to be that much more painful.
- Hold on to as much metadata as you can. You never know when it's going to come in handy.
- When tackling big migrations, break hard problems up into smaller, slightly easier problems.
- Document your thinking and your work along the way. It's too easy to get stuck going in circles on longer projects if you forget where you've already been.
- APIs are magical and user-facing services that don't have them should be avoided at all costs.
I think this concludes my 14.5 years of being a Flickr user. I've canceled my Pro subscription and plan to delete my account in the weeks ahead.
If you find any of these tools useful, or if you have a different approach, I'd love to hear about it.