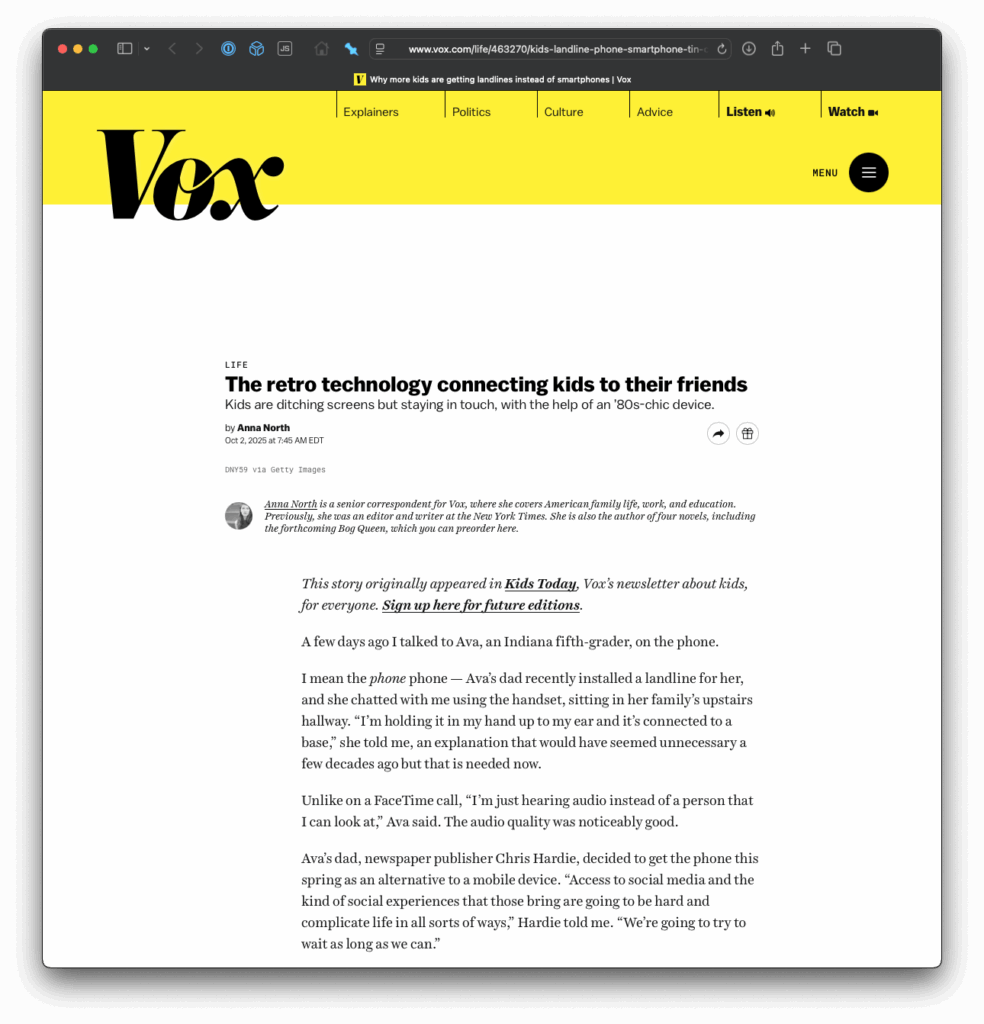
Vox reporter Anna North recently found my blog post about setting up a landline phone for kids and decided to learn more. She ended up interviewing both me and my daughter about it, and the resulting article was published today:
It was so fun to hear Ava describe this experiment to a reporter, including the use of the words "cringe" and "old-timey."
I recently finished a really interesting course in my graduate journalism studies program, focused on cross-platform, multimedia storytelling. It was fun in part because it wove together a lot creative disciplines I had already been experimenting with, including writing, photography, audio production, video production, interviewing people, and assembling the results of those efforts into a coherent, interesting final product that would engage the attention of readers and visitors. I got academic credit for doing things I love to do — nice!
It was also an experience that opened my eyes further to the power of the WordPress block editor for multi-media journalism and storytelling, and I want to share a bit more about that.
(If you're not already familiar with it, the WordPress block editor, also known as Gutenberg, is the updated content editing experience introduced into the WordPress publishing platform back in 2018. It transitions content authoring and editing in WordPress from a fairly linear "title plus paragraphs of text plus maybe some images" workflow into a much more flexible and powerful workflow that can include a wide variety of multi-media, interactive elements positioned throughout the body of a page or article. If you were talking to someone using a few tin cans and some string before, now you're enjoying the wonders of a smartphone.)
Like others I've had some skepticism in the past about the block editor and its place in the world of everyday WordPress users who may not want the additional power it offers. And at a personal level, old habits can die hard; I found myself writing this very post in the "classic" editor because it's how I've mostly always done things. So I haven't always been sure when and were I could definitively say to others that the block editor would be an essential part of their publishing toolkit.
The thing that I hadn't done yet, but now have and detail in this follow-up post, is to create an automated way to clean up references to Flickr-hosted photos that exist in an existing WordPress website or blog. Without this critical final step, one could have a lot of historical content that still references Flickr-hosted photos instead of the version being hosted on your shiny new WordPress-powered photo site.
So here's how I did it. As with my previous post, this information is geared toward a technical audience that is comfortable with the command line and possibly modifying PHP code to suit their own purposes.
Method
I thought about a couple of different ways I could handle this "find and replace" operation.
With 13 years of blog posts, many of which contain references to Flickr photos in some form, making the changes manually was not an option.
I thought about continuing to iterate on my existing PHP command line tool that takes the exported Flickr dataset and generates a WordPress import, which would mean creating some kind of lookup data file where a find-replace command would use the Flickr photo URL to find the new WordPress-hosted photo URL. But when I saw all of the different ways I had embedded Flickr photos in my blog post content:
on a line by itself for oembed rendering
as simple links to a Flickr photo page
as <a> plus <img> tag groups that displayed the images full size inline with a link
as <img> tag groups that displayed the images at various smaller sizes, aligned left or right
I realized that I would need to be able to lookup the proper image URL for each display scenario. And given that my WordPress-powered photo site generated different image sizes (and that some of these had changed since the original data migration), that was not going to be simple. No one-size-fits-all substitution would work.
The good news is that WordPress easily supports building a custom REST API endpoint that would support a dynamic lookup of the information I needed on the photo site, for use on any site where I was finding-replacing content. Once I realized I could decouple those operations, it was clear how to proceed.
Creating a "Find by Flickr URL" API Endpoint
The first step, then, was to create a REST API endpoint on my WordPress-powered photo site that would allow me to specify the original Flickr photo URL and find the related WordPress post that had been generated during the migration process.
If you look at the code of the original migration tool, you'll note that for each WordPress post it creates, it adds a post meta field _flickr_photopage where it stores the URL of the Flickr-hosted photo. That usually looks something like https://www.flickr.com/photos/myflickrusername/123456789/. We can use that post meta field to do a simple lookup of the equivalent WordPress post object.
Since I want to be able to retrieve an image URL at a specific size so that I'm not embedding full size, large image files in posts that only need, say, the 300 pixel wide version, I also needed to accept width and height parameters, and then do a lookup of the related attachment file URL in WordPress.
Nice! Now I have the permalink of the photo post that replaces the original Flickr photo page, the URL of the image media file I can use in an <img> tag, and some other meta info if I need it.
The Find-and-Replace WP CLI Plugin
Now, it's time to use that API endpoint in a big find-replace operation.
The clear choice was to make a WP CLI command that could be used to run this on the command line, where I could log and review warnings and errors and have better memory management.
In creating this command, I used this general approach:
Get all the posts in the WordPress database that mentioned a Flickr URL with my username in it
For each post found, look for specific kinds of Flickr link and image references that need to be replaced
Extract the original Flickr photo page URL from those references
Use the API endpoint created above to look up the corresponding information on the photo site
Update the post content with the information retrieved from the API
It sounds fairly simple, but I ran into several challenges and opportunities for optimization:
Not only were there references to the Flickr URL structure above, there were variations to consider such as the internal version of my Flickr user account ID that was in wider use years ago, or the flic.kr shortened version of their domain.
The API lookups could generate a lot of activity on my photo site, so I added some caching since those responses should rarely be changing.
I found some photos that I had apparently set to "private" or "contacts only" on Flickr but had left referenced in my blog posts, so I had to manually address those.
My Flickr-to-WordPress migration tool didn't handle Flickr "sets" (although it preserved and stored the data needed to handle the), so I had to redirect those references.
I had to make sure not to replace Flickr references to other people's photos.
Flickr varied its use of http versus https in different embed code it generated over the years.
In the end, I had a working plugin that could do a dry-run operation to see what it was going to change, and then do a "for real" run to actually update the posts as stored in the database.
$ wp flickr-fixer fix-refs --dry_run=false
Getting all posts containing Flickr references...
Found 203 posts to process.
Success: 621 replacement(s) made across all posts
With the API lookup cache primed, on my site it only took a minute or two to run. YAY!
(If you use it, you'll need to find/replace my Flickr username and a few other hardcoded references accordingly.)
Lessons Learned
When I think about the time I put in to first creating the original Flickr-to-WordPress migration tool, and then the time put into this content cleanup tool, it turns out it was a non-trivial project. But it always felt like the right thing to do, since once I was moved fully into WordPress I would have absolute control over my photo collection without depending on the changing services or business model of Flickr or anyone else.
It also highlights a few important lessons for migrations and owning your data online:
Try to be consistent in the ways you reference third-party tools and services in your content or workflows. If you have a bunch of variations and inconsistencies in place, any future move to another tool is going to be that much more painful.
Hold on to as much metadata as you can. You never know when it's going to come in handy.
When tackling big migrations, break hard problems up into smaller, slightly easier problems.
Document your thinking and your work along the way. It's too easy to get stuck going in circles on longer projects if you forget where you've already been.
APIs are magical and user-facing services that don't have them should be avoided at all costs.
I think this concludes my 14.5 years of being a Flickr user. I've canceled my Pro subscription and plan to delete my account in the weeks ahead.
If you find any of these tools useful, or if you have a different approach, I'd love to hear about it.
Yesterday I gave a talk at php[world] 2019 about "Tips and Tools for Gluing Together the Open Web." Below are the slides, text and links from my talk. Where applicable, the slide images link to relevant websites and code.
A few months ago, I was helping a local non-profit organization with their new website. We were almost set to launch, but they had one more request: can we get the next five upcoming events we've put up on our organization's Facebook page to show up in a list in the website's footer? I initially thought that surely there would be a simple way to do this, but as I looked in to it, the short answer was no, no you can't.
There's an embeddable Facebook widget that can display events, but you don't get a lot of control over appearance and it's far from a helpful list that can be scanned quickly. This seemed like such a basic request - connecting Facebook page events to a website - and yet as I poured through Google and Stack Overflow search results all I could find were frustrated users and abandoned tools that had tried and failed to do this one thing.
It might be hard to remember, but there was a time when Facebook wasn't the only place to learn about upcoming events in our communities. Instead of having to scroll past silly memes and political rants to get the details of the next potluck, lecture or book club you cared about, the information was available in lots of other places. Events were available on websites and apps, and they were shared via constantly updated feeds that you could even integrate directly into your own personal calendaring system.
You could learn about what was happening down the street or across town, and you didn't have to give up your online privacy to do it.
At some point, this shifted. Weary of the duplication of efforts maintaining event information in multiple places, and increasing fragmentation of sources that you needed to consult to figure out what's happening, people longed for a more centralized, authoritative spot to enter and learn about community events. I was one of those people.
Enter Facebook
Facebook saw this opportunity and jumped on it.
They made it easy to enter and promote events, and they sprinkled in social features to make it extra compelling to do. Not only could you learn about the event itself, you could see who among your friends was planning on (or interested in) going, and what they had to say about it. If you were an event organizer you could see what kinds of events were catching the interest of your target audience, and you could more easily avoid scheduling your big fundraising gala on the same night as the art museum open house.
At first, Facebook made access to event data one of the most friction-free parts of its platform, and they didn't require you to be "on Facebook" to see it. You could get email notifications, RSS feeds, ICS feeds to bring event information into your own productivity tools and daily life. There was API access so that you could build tools and websites that incorporated the event data where you wanted it to be.
Over time, all of that access was removed. The APIs were shut off, the feeds were shut down, and the message was clear: you have to come to the Facebook website or app to learn about events that you might want to attend.
It's nothing new to note that Facebook's user interface and business model are built around keeping people inside its walled garden. Whatever you might want to contribute to or get from your Facebook experience, they want you to do it on their website or in their mobile app, and on their terms. Their ability to sell advertising space depends on it.
But as with many other aspects of Facebook culture and its grip on our personal and community data, there's a significant downside. Facebook's decision to lock up event information has real implications for how we encounter and experience public life in our real-world communities.
Why is this a problem?
It means that like our exposure to news or updates from our online friends, our awareness of community events is driven by a black-box algorithm optimized around profit over everything else. It means that one company's shifting views on what constitutes an acceptable event, and its sensitivity to the interests of paying advertisers and political organizations could determine whether we see the details of an upcoming protest, demonstration or other exercising of free speech.
And it means that anyone concerned about the privacy implications of having their interest in a given event tracked, sold and monetized may have less exposure to the events that may have traditionally shaped and defined public life in their community, and private life in their circles of friends and neighbors.
There are practical implications too. An organization or business that still chooses to have its own website is having to enter and maintain event information in multiple places, which is time consuming and inefficient. People who want to avoid using Facebook are either left out of the loop or forced into using it again.
I went looking for solutions to this in the context of a website project I was working on recently, where the request was simple: can we bring our Facebook event data into our WordPress site? I had naively assumed that Facebook would have an interest in making this easy: if people could enter their events in one place and have them pushed out to everywhere that mattered, it would be so much easier to see them as the natural place to maintain that information.
But again, they don't make it easy. There's no API available to fetch event data, even for a Facebook page on which I'm an administrator. Event data is not displayed on public-facing Facebook.com pages in any kind of structured ways, and in fact it is rendered in ways that make it resistant to traditional "scraping" tools. There are no other user- or developer-friendly tools for working with event data that I can find.
Yes, Facebook does have a "page widget" that lets you display event information from a Facebook page elsewhere via embedding, if you are an admin on that page. The layout and customization options are pretty limited, but more importantly this is not the same thing as having access to the event information itself for importing, displaying, searching, archiving or other actions that someone might want to take.
Asking page owners to initiate displaying the event information elsewhere also eliminates the chance for other interested parties to "slice and dice" event data in potentially useful or interesting ways. If I want to create a website where you can search and display all of the animal adoption-related events in the Facebook facebook happening within 50 miles of my zip code, I can't. I can't do this even if all of the animal adoption agencies enter their events on Facebook, make them public and put page widgets up on their own website.
Can software fix this?
Being a software developer who works all day long on tools that try to make publishing easier and more interconnected, as I thought about this issue I still felt like there must be some way to extract event data from publicly shared Facebook events. After all, if you can see them in your web browser even while not logged in to Facebook, then that means the data is by definition publicly accessible in some form.
After analyzing the structure of a Facebook web page, its Javascript and the asynchronous HTTP calls made to fully render the content on it, I found that there is a way. Facebook's own event display pages are making a POST to the URL https://www.facebook.com/api/graphql/ to retrieve relevant event details, which are then rendered in HTML and CSS for a normal user to see. I sniffed the request and removed all of the query parameters I could find that might be extraneous. Here's an example of a resulting logged-out POST request that retrieves a batch of the upcoming events for a given Facebook page (my local Parks and Recreation Department):
I can't tell you what all of the query parameters mean but I think doc_id is the Facebook-internal indicator of a shorthand for which query to run (so apparently "2343886202319301" maps to "all upcoming events" or something like that) and pageID is the internal ID of the Facebook page itself. I can imagine this query breaking later on if Facebook decided to update the doc_id mappings, but for the time being, it works.
The result of the request is a JSON object that contains all the upcoming event info one would need to import Facebook events into another system, display them on a non-Facebook website, and so on.
From this point, I could imagine creating a tool that, given a list of Facebook pages, automatically and regularly grabs all of the upcoming public events available in Facebook and does something useful with them. Here's a proof of concept PHP script that lays the groundwork for that.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Does Facebook care if we access event data in this way? Yes, yes they do. Their terms of service about Automated Data Collection explicitly states that if you try to extract data from the Facebook platform in an automated way, they can ban you forever. But more likely than anything is that they will change the way their platform works to make this kind of data retrieval even more difficult.
I think there's hope for some shifting expectations about what's considered fair here. A U.S. appeals court ruled just last month that web scraping does not constitute illegal activity, and went so far as to acknowledge that if a scraper is retrieving publicly available data owned not by the platform but by its users, the scraping can't be blocked.
In the case of Facebook event data, it's worth noting again that we're talking about publicly available information shared by organizations that want it to get more exposure online about events that they want the public to attend. Restricting access to that because it's a potential source of advertising revenue seems beyond greedy to me. In the end though, it's up to organizations, businesses and individuals to decide whether they want to have their event data locked up, or out on the open web.
You can help
If you are an event organizer, please consider posting your event data outside of Facebook on a publicly available website!
If you are someone who cares about building a healthy culture of civic engagement in your community, advocate for the organizations you're involved with to move away from tools that make this harder in the long term!
If you are a developer at Facebook or anywhere else that builds tools for people to share information, please don't lock up that information! Show your commitment to the open web. Provide APIs, RSS (or in this case, ICS) feeds, good documentation and facilitate easy exports of user-owned data. (A quick shout-out to the folks at Eventbrite who, at least for now, make available for free a very robust API to access community events shared on their platform.)
I'm glad for any feedback and suggestions about these challenges; please comment below. I've also explored the themes discussed here in various past posts, including:
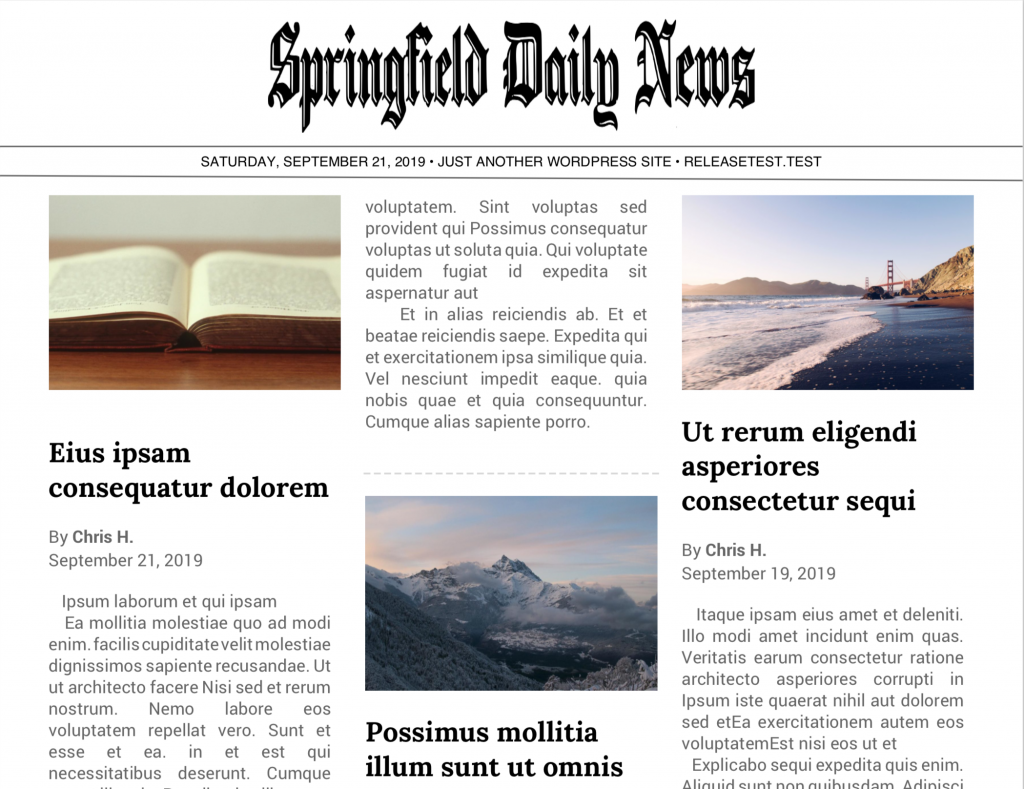
The plugin does one thing: it generates a newspaper-style PDF document from the posts on your WordPress site.
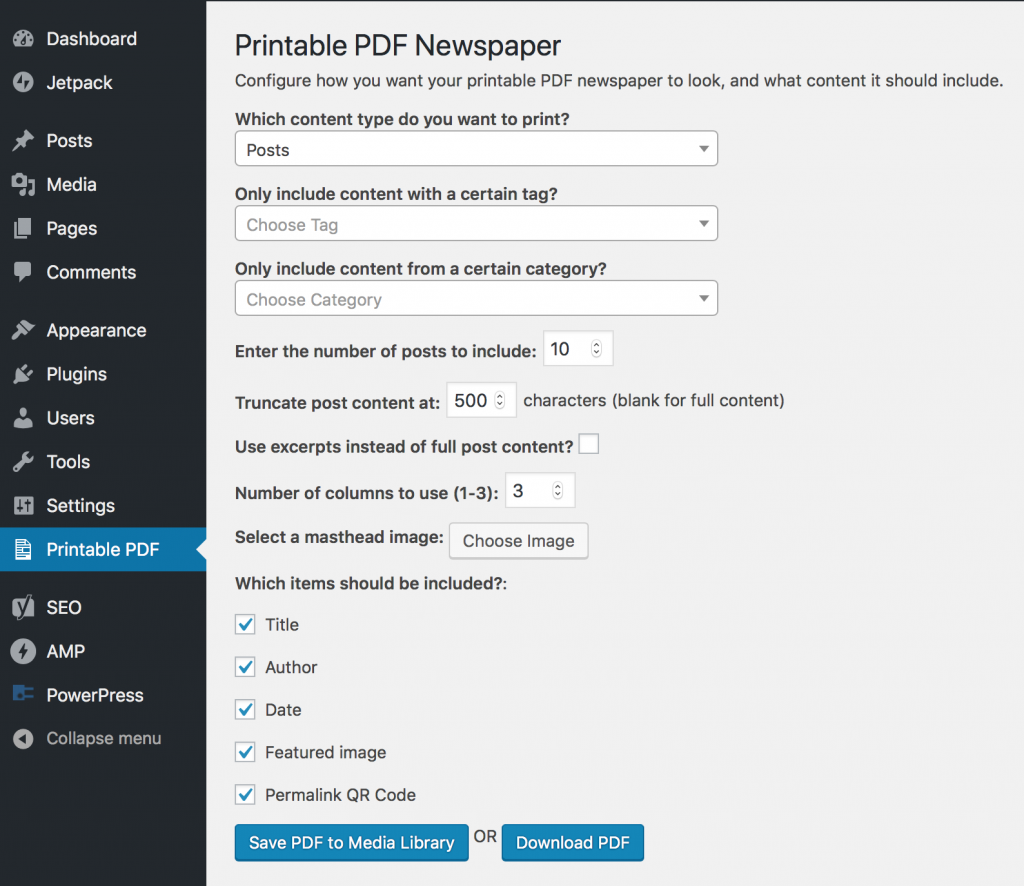
Pick which posts you want to include, customize a few things about how they're displayed, decide which fields to display (including a QR code that links a print reader with a smartphone back to your site), and generate the PDF. You can download it for printing or save it to your media library for easy linking and sharing.
That's it. That's the plugin.
There have been other plugins that do this kind of thing, but they were usually either reliant on a third-party PDF generation service, some of which required subscriptions, or they hadn't been updated in quite a long time so the architecture was out of date. Some allow you to generate a printable version of your website, but without the focus on a newspaper-style format.
So why would you want to generate a printed thing from your online site content?
Maybe you're producing a newsletter for your campus, neighborhood or community, and you want to take the information you've already published online and hang it up on a message board. Maybe you're a small news organization that wants to tease would-be subscribers at the local diner about what you have to offer. Maybe you just want to have something to look at over your own coffee in the morning. Whatever it is, some people still enjoy encountering things and ideas through engagement with objects in the physical world, and I hope this tool helps facilitate that for WordPress publishers of all sorts.
I've been thinking about the concept for this plugin for over a year, maybe more. I hadn't made time to actually work on building it, so I assumed the idea would just fade away. When it didn't and I still found myself really wanting to see this thing in the world, I contracted out the building of a first rough version, and then spent some time reworking it to my liking. It has rough edges and there are plenty of things it could do better, but I'm proud of it as a version 1.0.
I'll be presenting a session at php[world] in Washington, D.C. on October 23rd, "Tools and Tips for Gluing Together the Open Web." I get to combine a bunch of topics I'm interested in: the programming language that powers 83% of the web, tools and ideas for helping people own their online homes and content, the principles behind (and discussions happening around) strengthening the open web, the publishing platform that powers over a third of websites out there, and hacky little bits of "glue" software I've written to get data in or out of a given service.
I'm excited and it looks like a great conference. (My employer, Automattic, is an event sponsor.) If you're interested in PHP, software development and/or the open web and will be in the D.C. area then, I hope to see you there.
I've been running a personal WordPress multisite instance for several years now, and I use it to host a variety of personal and organizational sites, including this one. I really like the ways it allows me to standardize and consolidate my management of WordPress as a tool, while still allowing a lot of flexibility for customizing my sites just as though they were individual self-hosted sites.
For the most part, my use of WordPress in multisite/network mode doesn't have any user-facing implications, especially since I use the WordPress MU Domain Mapping plugin to map custom domain names to every site I launch. As far as anyone visiting my sites knows, it's a standalone WordPress site that looks and works like any other.
The one exception to this has been the URL structure for images and other attachments that I upload to any site hosted on this multisite instance. Whereas the typical WordPress image URL might look like this:
where 25 might be the site's unique site ID within that multisite setup.
There's nothing wrong with this approach and it certainly makes technical sense if you have lots of sites on your multisite instance that are either subdirectories or subdomains of the main multisite domain.
If you're ready to move your own Flickr photo collection to WordPress and feel comfortable on the command line, you can go straight to the Flickr to WordPress tool I built and get started.
I used to love Flickr as a place to store photos, and as a community for sharing and discussing photography. But as its ownership changed hands and its future became at times uncertain, I grew reluctant to trust that it could continue to be a permanent home for my own photos. My discomfort increased as I have become more engaged with the need to have full ownership over the things I create online.
So, I set out to migrate my 3.6GB collection of 2,481 Flickr photos, along with their tags, comments and other metadata, into a new home while I still could.
As an advanced publishing tool, WordPress typically defaults to displaying information about the author behind a given post or page on a WordPress site. But sometimes you want to build a website that has a more "singular" editorial identity, and that doesn't appear to be authored and managed by multiple people, even if it is. I see this regularly with corporate brands, political organizations, larger not-for-profits, and advocacy groups where the identity of a post or page's author could distract from the content being shared.
So how do you keep WordPress from revealing the author information - names, usernames and more - for the administrative users of your site? Here are a few tips, aimed at WordPress developers comfortable customizing their sites through changing the theme and plugin code.